Hybrid Clouds: are we there yet?
by Johan De Gelas on October 18, 2010 2:05 PM EST- Posted in
- IT Computing
Hybrid "Storage" Cloud
A good network connection between two datacenters is the first step. But things really get interesting when you can move your data quickly and easily to another place. Moving a VM (vMotion, Xenmotion, live migration) towards a new location is nice, but you are just moving the processing and memory part.
Moving a VM to a location that is hundreds of kms/miles away behind a firewall and letting it access storage over a long distance is a bad idea.
The traditional way to solve this would be a fail-over mirroring setup. One node is the "original" active node. This is the one that is written to: the application will send writes to handle an OLTP transaction for example. The other node is the passive node and is synced with the "original" one on a block level. It does not handle any transactions. You could perform a "fake" storage migration by shutting down the active node and letting the passive node take over. Nice, but you do not get any performance scalability. In fact, the "original" storage node is slowed down as it has to sync with the passive one all the time. And you can not really "move around" the workload: you must first invest a lot of time and effort to get the mirror up and running.
Another solution is simply merge two SANs to one. You place one SAN in a datacenter, and the other one in another datacenter. Since high-end optical fibre channel cables are able to bridge about 10 kms, you can build a "stretched SAN". That is fine for connecting your own datacenters locally, but it is nowhere near our holy grail of an "hybrid cloud".
Storage vMotion and vMotion are relatively affordable solutions to create a hybrid cloud at first sight. But at second thought, you'll understand that moving a VM between your private cloud and public cloud without down time will turn out to be pretty challenging. From the vSphere Admin guide:
"VMotion requires a Gigabit Ethernet (GigE) network between all VMotion-enabled hosts."
A dedicated gigabit WAN link is not something that most people have access to. And expanding the VLAN accross datacenters can be pretty hard too. It will work, but it is not supported by VMware (as far as we know) and will cause a performance hit. We have not measured this yet... but we will.
VM Teleportation
A little rant: I have learned to stay from presentations of quite a few vice presidents. Some of these VPs seem to be so out of touch with technical reality that I could not help wondering if they ever set foot in the tech company they are working for. What supposed to be a techy presentation turns out in an endless repitition of "we need to adapt to the evolving needs of our customers" and "those needs are changing fast". And then endless slides with smiling suits and skyscrapers.
Chad Sakac, the EMC VMware Technology Alliance VP, restored my faith in VPs: a very enthusiatic person which obviously spends a lot - probably too much - of time with his engineers in the EMC and VMware labs. Technical deep dives are just a natural way to express himself. If you don't believe me, just ask anyone attending the sessions at VMworld or EMCworld or watch this or this.
Chad talked about EMC's "VM teleportation" device, the EMC vPlex. At the physical level, the vPlex is a dual fully redundant Intel Nehalem (2.4 GHz) based server with 4 redundant I/O modules.
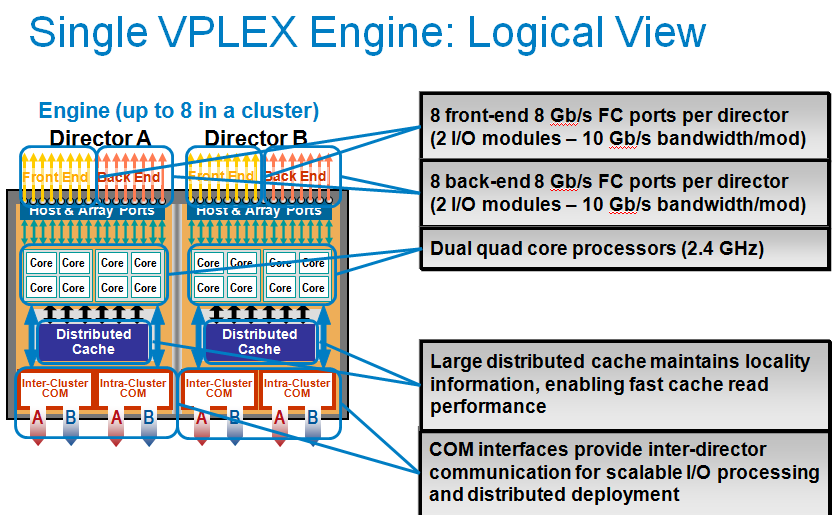
Click to enlarge
Each "Director" or Nehalem Server has 16 - 64 GB of RAM. Four GB is used for the software of the VPLEX engine, the rest is used for caching.
The VPLEX boxes are expensive ($77000) but the VPLEX engine does bring the "ideal" hybrid closer. Place one VPLEX in each datacenter on top of your SANs (can be EMC or other).
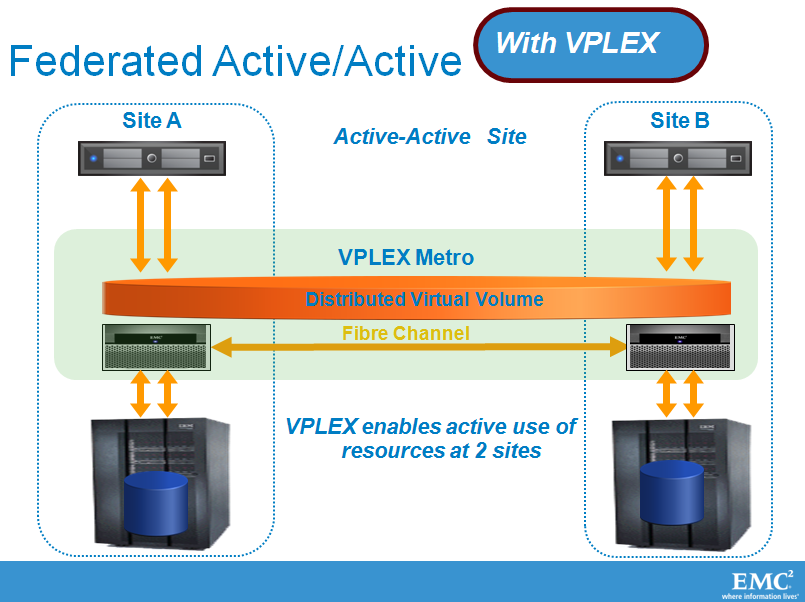
Click to enlarge
The cool thing about this VPLEX setup is that it is able to move a large VM (and even several large ones), even if that VM belongs to heavy OLTP database server, over to a remote datacenter very quickly and with acceptable performance impact.
Of course EMC does not disclose fully how they have managed to made this work. What follows is summary of what I managed to jot down. Both datacenters have part of the actual storagevolumes and are linked to each other with at least 2 fast FC network links. The underlying SANs have probably some form of networking RAID similar to the HP lefthand devices.
The virtual machine and data that is being moved, uses "normal" vmotion (no storage vmotion) towards the other datacenter. The VM can thus start immediately after the end of vmotion, after copying the right pages of the original host's memory. That takes only a minute or less, and meanwhile the VM keeps responding. The OLTP application on top is not disrupted in any way, just slowed down a bit. You can see below what happened when 5 OLTP databases were moved. A Swingbench benchmark on top of these VMs measured the response time before, during and after the movement of the 5 VMs.
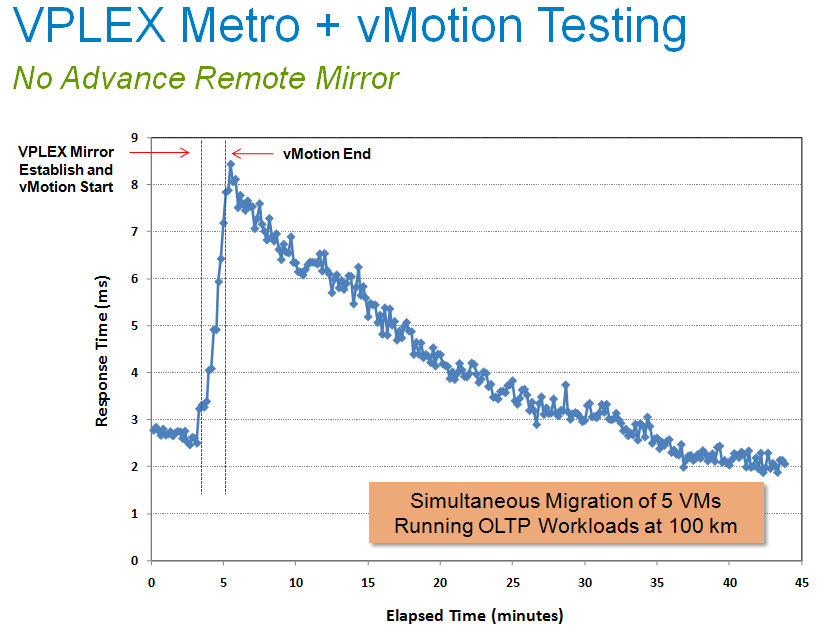
As the cache of the remote VPLEX device is "cold", it needs to get a lot of data from the other side. The remote VPLEX cache gets a lot of cache misses at first. So if you run a transactional load in the VM, you will notice higher latency after the vMotion: about 2.5 times higher (7.5 instead of 3 ms). After some time (40 minutes in this case), the second cache is also filled with the most requested blocks.
A directory based distributed cache coherence makes sure the VPLEX node can answer to the I/O requests, whether it be reads or writes. This is very similar to directory based CPU caches (here: the VPLEX cache) and how they interact with the RAM (here: the distributed "network RAID" virtual storage volume).
The underlying layer must take care of the rest: writes should not happen in both datacenters on the same block. So in the case of vMotion, the writes will be written by the VM that is active. So if the vmotion is not over yet, writing will happen first on the original location, and once the VM has been moved, the changes will be written at the new location.
EMC call this VPLEX device a geo disperse, cache coherent storage federation device. Right now the VPLEX METRO allows synchronous syncing over a distance of 100 km. The requirements are pretty staggering:
- An IP network with a minimum bandwidth of 622 Mbps
- The maximum latency between the two VMware vSphere servers cannot exceed 5 milliseconds (ms), about 100 km with a fiber network.
- The source and destination ESX servers must have a private network on the same IP subnet and broadcast domain.
So this is definitely very cool technology, but only for companies with deep pockets.

Click to enlarge
EMC does not want to stop there. A few months ago EMC anounced VPLEX Metro (5ms or about 100 km) synchronous. In 2011, the VPLEX family should be able to bridge 1000 km using asynchronous syncing. Later, even higher distances will be bridged.
That would lead to some massive migrations as you can see here. More info can als be found on Chad's personal blog.








26 Comments
View All Comments
pjkenned - Monday, October 18, 2010 - link
Stuff is still new but is pretty wow in real life. Clients are based on Android and make that Mitel stuff look like 1990's tech.Gilbert Osmond - Monday, October 18, 2010 - link
I enjoy and benefit from Anandtech's articles on the larger-picture network & structural aspects of contemporary IT services. I wonder if, as Anandtech's readership age-cohort "grows up" and matures into higher management- and executive-level IT job positions, the demand for articles with this kind of content & focus will increase. I hope so.AstroGuardian - Tuesday, October 19, 2010 - link
FYI it does to some extent... :) "You can't stop the progress" right?JohanAnandtech - Tuesday, October 19, 2010 - link
While we get less comments on our enterprise articles, they do pretty well. For example the Server Clash article was in the same league as the latest Geforce and SSD reviews. We can't beat Sandy Bridge previews of course :-).And while in the beginning of the IT section we got a lot of AMD vs Intel flames, nowadays we get some very solid discussions, right on target.
HMTK - Tuesday, October 19, 2010 - link
Like back then at Ace's? ;-)rbarone69 - Tuesday, October 19, 2010 - link
You couldn't have said it better! As an IT Director find information that this site gives invaluable to my decision making. Articles like this give me a jumping off point to thinking outside the box or adding tech I never heard of to our existing infrastructure.What's amazing is that we put very little in new equipment and are able to do what cost millions just 10 years ago. We can now offer 99.999% normal availability with only a maximum of 30minutes of downtime during a full datacenter switch from Toronto to Chicago!
The combination of fast multi core processors, virtualization tech and cheaper bandwidth have made this type of service availalbe to companies of all sizes. Very exciting times!
FunBunny2 - Monday, October 18, 2010 - link
The problem with Clouding is that systems are built to the lowest common denominator (which is to say, Cheap) hardware. The cutting edge is with SSD storage, and it's not likely that public Clouds are going to spend the money.Mattbreitbach - Monday, October 18, 2010 - link
I actually see this going forward. I would put money on public cloud hosts offering different storage options, and pricing brackets to match. I also do not believe that many of the emerging cloud environments are being build with the cheapest hardware available. I would be more inclined to think that some of the providers out there are going for high-end clients who are willing to shell out the cash for performance.mlambert - Monday, October 18, 2010 - link
3PAR, HDS (VSP's) and soon EMC will all have some form of block/page/region level dynamic optimization for auto-tiering between SSD/FC-SAS/SATA. When the majority of your storage is 2TB SATA drives but you still have the hot 3-5% on SSD the costs really come down.HDS and 3PAR both do it very well right now... with HDS firmly in the lead come next April...
The problem I see is the 100-120km dark fiber sync limitation. Once someone figures out how to be sync with 20-40ms latency (or the internets somehow figure out how reduce latency) we will have some pretty cool "clouds".
rd_nest - Monday, October 18, 2010 - link
Not willing to start another vendor war here :)Wanted to make a minor correction - EMC already has dynamic sub-LUN block optimization..Also called FAST - fully automated storage teiring like you mentioned. This is in both CLARiiON and V-Max...the implementation is different, but works almost same.
Don't you feel 20-40ms is bit too much?? Most database applications/or any famous MS applications don't like this amount of latency. Though quite subjective, I tend to believe that 10-20ms is what most people want.
Well, I am sure if it is reduced to 10-20ms, people will start asking for 5ms :)