Setting up the Google Mini
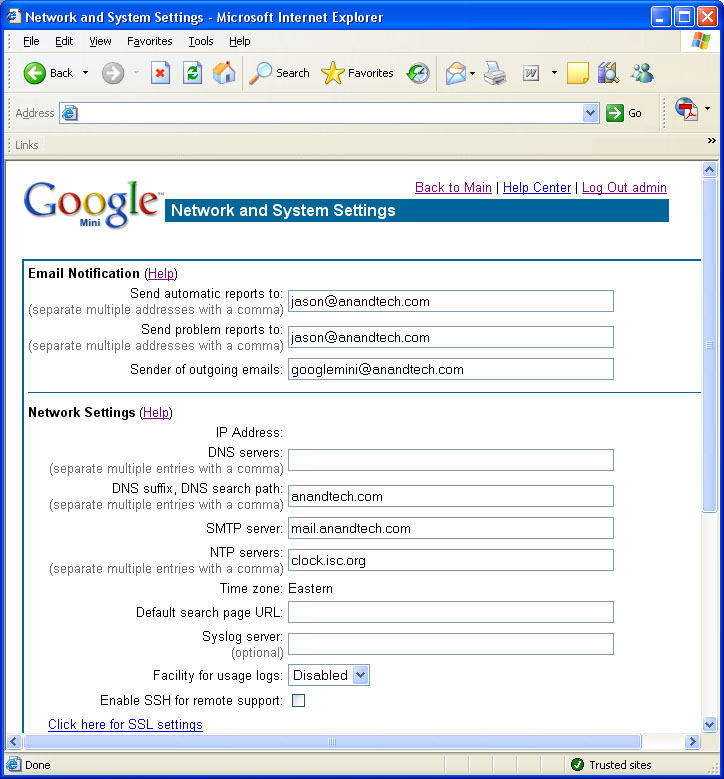
When you first login to the Google Mini, you are presented with a web-based interface to configure the general parameters. These settings include the device IP Address, DNS Server, Admin E-mail address, Time zone, etc. Nothing fancy here, although we did have to configure an internal DNS server due to some firewall routing issues.Configuring your first Collection
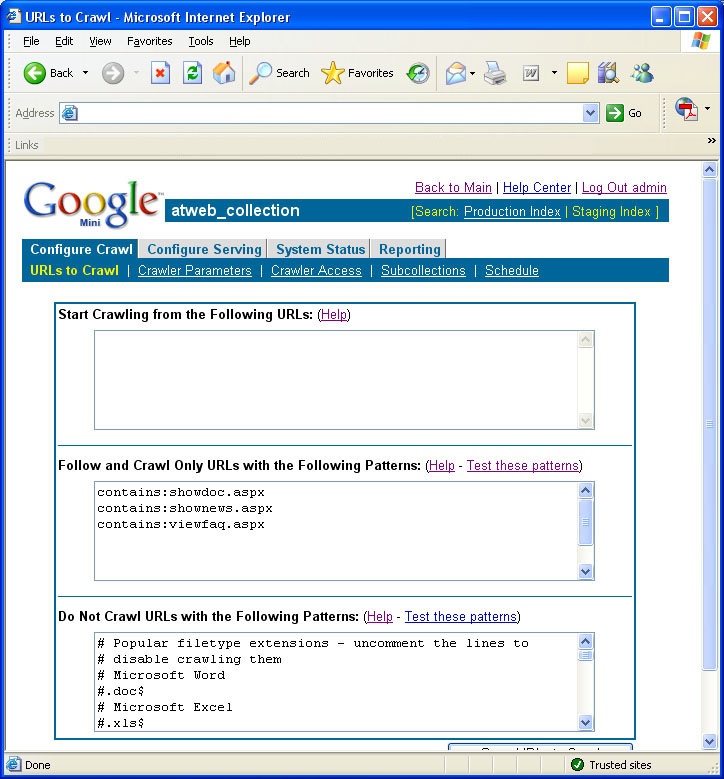
Like most any search product, the first task is to create a collection of what you want searched. The Google Mini supports one collection while its larger brother, the “Google Search Appliance, supports an unlimited number of collections. Collections can contain sub-collections (which I’ll explain a bit later).Once you’ve created your first collection, the first step is to edit the collection parameters and set it up for indexing. URLs to Crawl was where we started, which contains a few parameters, Starting URLs from which to crawl, Follow and Crawl certain URLs or parts thereof and Do Not Crawl URLs matching certain patterns. This was probably where we spent 99% of our time configuring the Mini. The mini allows for 100,000 documents/URLs to be stored in a collection, and AnandTech contains approximately 40,000 articles, news and blog entries.
When we first set up the Mini, we told it to start in each of the website’s sections (for example, http://www.anandtech.com/it/) and in the web news area. The Mini considers any unique URL string to be a unique document, which makes sense (but is a bit surprising the first time that you run an index).
After four hours of indexing, the Mini had managed to reach its document limit and we had to improvise. After several attempts at filtering out various URL patterns and restricting the crawling as much as we could, we ended up writing some code. We created a file to which a link to every article, news post and blog post that have been published on the site would be dumped. That file is cached for a few hours as we update the index 3 times a week. We then configured the Mini to start at those URLs and restricted it only to URLs ending in showdoc.aspx, shownews.aspx and a few others. It worked - the next index was around 38,000 documents. A word to the wise: don’t let the Mini crawl your entire site without keeping a close eye on it.
Sub-collections
Before you let the Google Mini go off and crawl to its hearts content, consider creating some sub-collections if they are required. Sub-collections are simply small collections containing specific fragments of your site. For instance, on AnandTech, we have Articles, News, Blogs and FAQs as sub-collections. Each of these can be searched separately within the collection to allow us to have targeted searches within the various sections of the web site.KeyMatch/Synonyms
Like the google.com search, the Google Mini supports key matches that allow you to have links appear at the top of your search results, which match keywords that you enter in the Google Mini interface. Another useful feature that is included is Synonyms, which allow you to enter synonyms for various search terms. We have a few created. Try typing “ iram” into our search, and you’ll notice that it suggests “i-ram” as a possible search.Look and feel integration
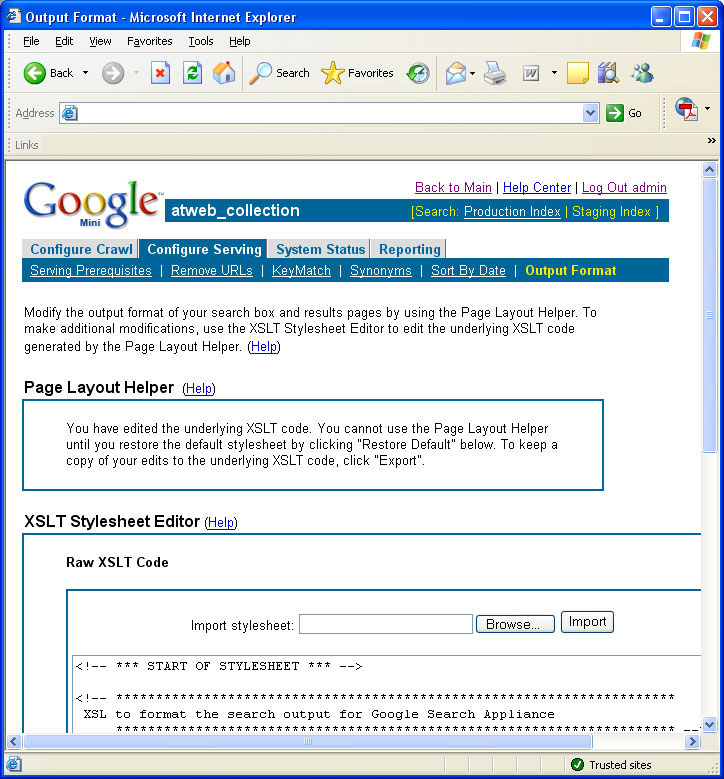
The last thing that we worked on was making the Mini look like it is part of AnandTech.com. There are two ways to go about this in the Mini admin. One is to use their built-in page layout helper, which allows you to wrap the search screens with a custom header and footer. The other way (which we prefer) is to use the XSLT Stylesheet editor and modify the stylesheet to meet your needs.All in all, our integration went fairly smoothly, and the Mini has made it exponentially easier to find content on AnandTech.com.
Screen Shots
 Settings |
 Collection |
 Output |
 Subcollections |








48 Comments
View All Comments
Jynx980 - Monday, September 5, 2005 - link
Interesting read, I don't understand a lot of it, but interesting none the less. Were you nervous cracking it open? I'd be sweating like Roger Ebert if I was trying to crack open a $3000 pizza box.Netopia - Monday, September 5, 2005 - link
How long before we see a big brother for it caching the forums?Joe
PorBleemo - Monday, September 5, 2005 - link
Waaaay too much information in the forums. You would max out the higher-end model easily.Marlin1975 - Monday, September 5, 2005 - link
Can you just not buy the software and install on your own hardware? Heck a 686b southbridge, does VIA even make those anymore, let alone SDRAM? That box must have had a lot of dust on it.coomar - Monday, September 5, 2005 - link
so searching on anandtech is going to be using google search enginei didn't know microsoft was responsible for the engine used right now
Verdant - Monday, September 5, 2005 - link
i would hardly say microsoft was responsible... it was SQL server, but you can hardly say it is a search engine in a boxbellwether - Thursday, November 29, 2007 - link
Not that Google's search is much better (from a visual stand point). Heck, you had to have people develop http://www.components4asp.net/GoogleMini/">google mini add-ons so it could do things like show image previews and have a layout that doesn't look like a Google search.leexgx - Friday, December 21, 2007 - link
adding an comment to this is fun when last post was like 2 half years ago heh